
精通
英语
和
开源
,
擅长
开发
与
培训
,
胸怀四海
第一信赖
精通
英语
和
开源
,
擅长
开发
与
培训
,
胸怀四海
第一信赖
锐英源精品开源心得,禁止全文或局部转载,禁止任何形式的非法使用,侵权必究。本文部分内容来源于英文论文pdf的翻译,因为pdf广为流传,部分权益归论文作者所有。
锐英源软件近期用kaldi训练出模型,模型在识别软件里表现完美,所以对于kaldi的功能深感佩服。同样,对kaldi相关的生态开源项目都有深厚兴趣,现在kaldi开发者正在推出kaldi2,研究kaldi2时,看到了PYKALDI2项目,对于PYKALDI2提出的序列训练,用识别结果扩充训练模型,同时服务器的分析输出参数能优化前端输入的机制,对2个PYKALDI2优势点非常着迷,但开源项目和产品还是有一定距离,但对产品研发也有借鉴意义。
看本文的朋友也可以着重看这2个优势,欢迎互相交流。再次强调,本文部分内容是国外广为流传pdf文件的翻译,部分权益归pdf作者所有。
此网页随后会推出PYKALDI2的一些代码分析,欢迎关注头条号:软件技术及人才和养生。
python是快速开发语言,python通过库方式能够调用C和C++高性能模块,这样让python方便扩充功能,也方便开发人员进行快速开发。其它的快速语言也有这个优势,比如C#语言里有VLC播放器的封装库,有了VLC封装库,C#开发播放器就很轻松了。
python的这个优势也是python能够在机器学习领域大放光彩的基础,较少的代码量能实现很多功能,自然开发人员能够接受。
我们介绍了基于 Kaldi 和 PyTorch 实现的 PyKaldi2语音识别工具包。虽然在两者之上构建了类似的工具包,但 PyKaldi2 的一个关键特性是使用 MMI、sMBR 和 MPE 等标准进行序列训练。特别是,我们在模型训练期间使用动态格生成实现了序列训练模块,以简化训练流程。此外,工具包中还实施了无格的 MMI 训练的初步版本。为了解决实际应用中具有挑战性的声学环境,PyKaldi2 还支持动态噪声和混响模拟,以提高模型的鲁棒性。有了这个特性,就可以将梯度从序列级损失反向传播到前端特征提取模块,这有望促进前后端联合学习方向的更多研究。我们在 Librispeech上进行了基准实验,并表明 PyKaldi2 可以达到具有竞争力的识别准确度。该工具包是在 MIT 许可下发布的。
在过去的几年里,语音识别技术的研究和应用都取得了巨大的进步,这主要归功于语音处理深度学习方法的采用,以及开放的可用性。源语音工具包,如 Kaldi [1]、PyTorch [2]、Tensorflow [3] 等。 作为最受欢迎的开源语音识别工具包,Kaldi 拥有自己的深度学习库和神经网络训练配方然而,将 Kaldi 与主流深度学习工具箱(如 TensorFlow 和 PyTorch)连接起来的需求一直存在。首先,连接将使Kaldi模型在TensorFlow或PyTorch的环境下进行推理成为可能,这从语音应用的角度来看是特别理想的。其次,该连接可以访问 TensorFlow 或PyTorch 中丰富的API 集,用于训练 Kaldi 模型,例如分布式并行训练包。最后但并非最不重要的一点是,由于深度学习工具包广泛用于其他模态,例如图像和自然语言,因此这种连接对于语音的多模态学习(例如视听处理)可能特别有用。
在这项工作中,我们介绍了 PyKaldi2,它结合了 Kaldi和 PyTorch 在语音处理方面的优势。该工具包建立在 PyKaldi [4] — Kaldi 的 Python 包装器之上。虽然已经有类似的工具包构建在 Kaldi 和 PyTorch 之上,例如 [5],但 PyKaldi2 的不同之处在于更深入地集成了Kaldi和 PyTorch,感谢 Kaldi 的python 包装器。特别是,[5] 的工具包在撰写时仅支持使用交叉熵 (CE) 标准的模型训练,而 PyKaldi2 支持 CE 训练以及序列判别 (SE) 训练标准包括最小互信息 (MMI)、最小语音错误 (MPE) 以及状态级最小贝叶斯风险 (sMBR)。为了简化序列训练管道,我们采用了动态晶格生成的工作流程,其中涉及 CPU-GPU 交错计算。虽然在模型训练期间即时生成格子可以简化训练管道,但缺点是它也会减慢训练速度。为了缓解这个问题,我们利用了 Pytorch 中的分布式并行训练框架,例如 Horovod 库 [6],它可以显着提高 PyKaldi2 中序列训练的效率。为了提高模型的鲁棒性,该工具包还支持动态噪声和混响仿真。
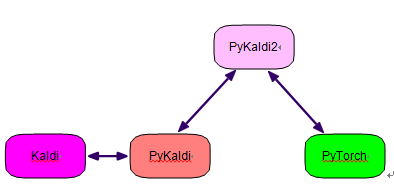
图 1. PyKaldi2 建立在 Kaldi、PyKaldi 和 PyTorch 之上。 PyKaldi 是 Kaldi 的Python 包装器,用于访问 Kaldi 功能。 PyTorch 主要用于训练神经网络。
我们在 Librispeech 公共数据集 [7] 上进行了基准实验。我们表明 PyKaldi2 可以实现有竞争力的识别准确度,并且序列训练可以导致持续改进。本文的其余部分安排如下。我们首先在第 2 节中概述了 PyKaldi2 的架构。在第 3 节中,我们解释了 PyKaldi2 中模拟、序列判别训练和分布式并行训练框架的实现细节。在第 4 节中,我们展示了我们在 Librispeech 语料库上的基准实验结果。第5节总结了本文。
PyKaldi2 的顶层架构如图 1 所示。我们利用 Pykaldi 来访问 Kaldi 功能。特别是,任何涉及隐马尔可夫模型(HMM) 和有限状态传感器 (FST) 的选项都在 Kaldi 后端执行。 PyTorch 主要负责神经网络训练。目前,PyKaldi2 仍然依靠 Kaldi 进行 bootstrapping,即定义 HMM 拓扑、构建语音决策树以及生成初始强制对齐等。
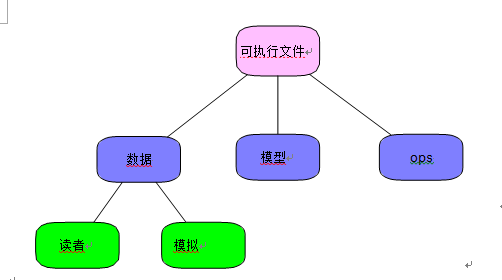
图 2.PyKaldi2 中模块的布局。
PyKaldi2的关键模块组织在以下文件夹中,如图2所示。
数据模拟是提高模型在不利环境下的鲁棒性的有效方法。典型的仿真过程包括将干净的语音波形与 RIR 进行卷积,并将输出与不同类型的噪声相加,以产生混响和嘈杂的语音。在静态模拟中,模拟语音是在模型训练之前生成的,噪声条件和 RIR 的组合范围有限。在 PyKaldi2中,我们实现了动态数据模拟,它在模型训练期间为每个话语随机选择一个噪声条件和一个 RIR。优点是对于不同的epoch,模型可以看到来自不同噪声和混响条件组合的数据,可以更高效、灵活地提高模型的鲁棒性。 PyKaldi2 支持单通道和多通道数据模拟,以及单扬声器源和多扬声器源模拟。
在典型的序列训练管道中,例如在 Kaldi 中,格通常首先使用种子(CE)模型以批处理方式生成,然后通过对格进行重新评分来计算损失来执行序列训练。 PyKaldi2 中的序列训练管道是
表 1. Pykaldi2 中带有静态比对的序列训练管道。
输入:
模型 - 种子神经网络声学模型 X1:T - 从 1到 T 索引的声学帧对数先验 -每个绑定 HMM 状态的对数先验
对齐 - 以过渡索引的形式强制对齐
HCLG-用于格生成的 Kaldi解码图
词 ID:词到索引的映射
trans模型:Kaldi 转换模型
1:设置Kaldi解码器
#调用 Pykaldi API
asr解码器 = MappedLatticeFastRecognizer(反式模型, 词 ID,解码器选项)
2:计算对数似然
#使用 PyTorch 在GPU上运记录喜欢 = 模型(X) -记录先验
3:晶格生成
# 调用 PyKaldi API,运行在 CPU 解码器上 out =asrdecoder.decode(log likes)
4:计算backpro的梯度
#调用 PyKaldi API,在CPU 上运行
loss=LatticeForwardBackward(反式模型, 记录喜欢,解码器输出[“格子”],盟,
标准=“mmi smbr mpe”)loss.cuda()#将梯度 移动到GPU
5:模型更新
loss.backward() #在 GPU 上运行,使用PyTorch 优化器.step()
不同之处在于格子总是在模型训练期间即时生成。这种设计的一个原因是使序列训练管道更简单。更重要的是,该方法可能更适用于超大规模数据集,因为格子总是由匹配良好的模型生成。序列训练流水线的骨架如表 1 所示。
当更好的声学模型或更多的训练数据(例如 Kaldi 中的标准训练管道)可用时,声学模型训练通常涉及多次刷新强制对齐。虽然此管道也适用于 PyKaldi2,但我们还使用动态对齐生成实现了模型训练。与在线格生成的动机类似,该方法可以降低系统构建的复杂性,甚至可以在某些具有大量训练数据的情况下提高模型的质量。表 2 显示了同时使用动态网格和比对进行序列训练的示例。
PyKaldi2 中的序列训练涉及跨 CPU-GPU 计算,如表 1 所示。如果我们只使用单线程,由于在线格生成,训练速度可能会很低。为了缓解这个问题,我们使用 Horovod库——一种更高效的 ring-allreduce 同步技术的实现——用于分布式并行训练。在我们的基准实验中,它可以通过利用多个 GPU 和 CPU,显着提高训练速度。未来,我们还将实现多 CPU 线程的格生成,这是目前阻碍训练速度的瓶颈。
表 2. Pykaldi2 中的序列训练管道,具有即时比对生成。
输入:
模型 - 种子神经网络声学模型 X1:T - 从 1到 T 索引的声学帧对数先验 -每个绑定 HMM 状态的对数先验文本 - 词级地面实况转录树 - HMM 状态绑定的决策树 L.fst- 词典第一次
HCLG-用于格生成的 Kaldi解码图
词 ID:词到索引的映射
trans模型:Kaldi 转换模型
1:设置Kaldi解码器和对齐器
#调用 Pykaldi API
asr解码器 = MappedLatticeFastRecognizer(反式模型,
HCLG,
单词 ID,
2:计算对数似然
#使用 PyTorch 在GPU上运行跨模型,
树,L, 对齐选项)
记录喜欢 = 模型(X) -记录先验
3:晶格生成
# 调用 PyKaldi API,运行在 CPU 解码器上 out =asrdecoder.decode(log likes)
4:对齐生成
#调用 PyKaldi API,在CPU 上运行 align out= aligner.align(log likes, text)
5:计算backpro的梯度
#调用 PyKaldi API,在CPU 上运行
loss=LatticeForwardBackward(反式模型,
记录喜欢,
解码器输出[“格子”],对齐输出[“对齐”],
| |
标准=“mmi smbr mpe”)loss.cuda()#将梯度 移动到GPU
5:模型更新
loss.backward() #使用 PyTorch 在GPU上运行
优化器.step()
我们使用公开的 Librispeech 语料库 [7] 进行了基准实验,该语料库总共包含大约 960 小时的训练数据。除非另有说明,否则我们的大部分实验都是在具有 4 个 Tesla V100 GPU 的单台机器上进行的。在神经网络模型方面,我们使用标准的双向 LSTM 进行声学建模,它有 3 个隐藏层,每层有 512 个隐藏单元。参数总数在2100万左右。我们在 [8] 中展示了来自基于变压器的声学模型的一些额外结果,该模型具有用于序列训练的动态晶格生成。我们使用了 80 维原始 log-melfilter-bank 特征,我们没有做任何形式的扬声器级特征归一化。相反,我们只应用了话语级别均值和方差归一化。我们使用了 4-gram 语言模型,作为语料库的一部分发布的解码。我们使用了 Kaldi建立一个高斯混合模型 (GMM)系统进行自举。
表 3. 使用960 小时 Librispeech数据训练的模型的结果。
模型 |
loss dev-clean dev-other test-clean test-other |
BLSTM |
CE 4.6 13.3 5.1 13.5 |
表 4. 序列训练的静态与动态比对。该模型使用 960 小时的训练数据和 MMI 标准进行训练,并在开发者其他评估集上进行测试。
结盟 |
0 |
1000 |
#脚步 |
4000 |
8000 |
静止的 |
13.32 |
12.28 |
12.24 |
12.17 |
12.14 |
动态的 |
13.32 |
12.33 |
12.31 |
12.28 |
12.24 |
我们使用来自 Librispeech 的 960 小时干净的训练数据报告 PyKaldi2 的基准测试结果。语音决策树和力对齐是从 Kaldi GMM 系统获得的。绑定的 HMM 状态的总数为 5768。对于 CE 训练,我们使用 Adam 优化器,初始学习率为 210-4,并从第 4 个时期开始将学习率降低 0.5 倍。我们训练了 8 个 epochs 的模型。然后我们使用 CE 模型作为种子,并将学习率固定为 1 10−6,并使用vanilla SGD 优化器进行 MMI、sMBR 和 MPE 训练。对于序列训练,我们使用 4 个 GPU 和 Horovod,每个 GPU 每次更新消耗 4 个话语,对应于小批量大小为 16 个话语。为了避免过度拟合,我们应用了权重为 0.1 的 CE 正则化。我们首先使用来自 GMM 系统的固定对齐进行实验。在我们的实验中,我们观察到序列训练收敛得非常快,并且在 8000 步左右达到了最佳结果。词错误率 (WER)结果如表 3 所示。 总体而言,序列训练在干净条件下可以实现约 5-6%的相对WER 减少,在其他条件下可以实现超过 7%,这表明序列训练流水线PyKaldi2 按预期工作。
然后我们展示了一些关于 PyKaldi2 训练速度的信息。虽然训练速度因包括用于训练模型的 GPU 类型在内的因素而有很大差异,
表 5. 不同GPU 数量和 minibatch 大小的训练速度统计。
表 6. 使用数据模拟训练的模型的结果。
模型 |
loss batch大小# GPUsi RTF |
BLSTM |
CE 64 1 190 |
声学模型的类型和大小,GPU 之间的数据连接,以及每个 minibatch 的大小等,我们根据我们的实验配置展示了一些统计数据,让读者一瞥 PyKaldi2 的训练速度。为了评估训练速度,我们在训练中使用了倒置实时因子 (iRFT) 的度量,它衡量我们每小时可以处理多少小时的数据。请注意,我们实验中的声学采样率为 100 Hz。鉴于此,我们还可以将 iRTF 转换为每秒帧数的度量。较低的采样率通常会显着提高训练速度。表 5 显示了 CE 和 MMI 训练的速度。 sMBR 和 MPE 训练的 iRTF 与 MMI的非常相似。对于 CE 训练,每个 minibatch 的序列长度是上下文窗口的大小,在我们的实验中设置为 80。对于 SE 训练,每个 minibatch 的序列长度是可变的,即 minibatch 中最长话语的长度。
表 5 显示了单 GPU 和多 GPU 作业的训练速度。对于CE 和SE 训练,多 GPU 训练的加速是显着的。当仅使用 1个 GPU 进行训练时,将批量大小从 1 增加到 4 只会使 SE 训练的速度提高约 1.5 倍。原因是当前实现中的每个小批量中的格生成和前向后向计算没有并行化。通过 Horovod 的多 GPU 训练,我们可以并行运行格生成以及 SE 损失的计算,这大大提高了训练速度。例如,如果我们将每个 GPU 的 minibatch大小设置为 4,则每次模型更新可以使用4 个 GPU 处理 16 个话语,训练速度可以达到每小时 50 小时左右的训练数据。使用 16 个 GPU,iRTF 可以达到 170 多个。
为了评估 PyKaldi2 的模拟模块,我们通过在会议室中重放 Librispeech dev-clean 评估数据来收集数据集1。该数据集由多个扬声器的模拟会议组成,这些会议由扬声器重放。然后数据由会议室中间的麦克风阵列记录。该数据集总共有 10 小时的记录,分为 10 个会话。每个会议有6个迷你会议,每个迷你会议有10分钟的录音,重叠率从0到40%不等。对于我们的评估,我们仅在中央麦克风记录的数据上测试了模型,这是没有波束成形的典型远场条件。
在我们的数据模拟实验中,我们使用了来自各种来源的噪声并模拟了 RIR。特别是来自 CHiME-4 挑战 [9]、DEMAND 噪声数据库 [10]、MUSAN 的附加噪声文件、语料库 [1、Noisex92 语料库 [12SE 2017 [非语音OSU 语料库 [14]。 RIR 都是模拟的,每个都有采样的房间大小、源和麦克风位置以及 T60 混响时间。 T60 时间从 0.2 到 0.5s 均匀采样。表 6 显示了使用和不使用数据模拟训练的模型的结果。在远场条件下,带有模拟的 460 小时干净语音的 CE 训练模型的表现甚至优于带有 960 小时数据的 MMI 训练模型,这表明 PyKaldi2 中的数据模拟模块工作得相当好。在这个实验中,我们对每个小批量进行了动态模拟,因此,由于不匹配,我们的模型在近距离通话条件下表现不佳。在工具包中,我们引入了一个控制模拟频率的选项,以便我们可以调整每个训练时期的原始声学数据的百分比。然而,我们没有通过调整模拟频率来重新训练模型,因为本文的重点不是在这个模拟评估集上获得最佳结果。

无格的 MMI (LFMMI) [15] 训练的核心功能也已在工具包中实现。 LFMMI 中的前向-后向算法在 Kaldi [1]的实现中运行在 GPU 上。为了充分利用 GPU 的计算能力,Kaldi 中的训练配方将训练数据中的话语分割成相同长度的块,例如 1.5 秒,并且每个小批量有多个序列,例如128. 要在 PyKaldi2 中重现类似类型的训练配方,它需要一种尚未完成的新型数据加载器。我们使用与基于格的序列训练相同的数据加载器在 PyKaldi2 中测试了 LFMMI 模块,小批量大小为 1,并在 dev-clean 上实现了超过 8% 的 WER,这比基于格的序列训练差得多结果。专门用于 LFMMI 的新数据加载器和数据预处理方案将在可用时发布。
我们介绍了 PyKaldi2——一个基于 Kaldi 和 PyTorch 开发的语音工具包。感谢 Kaldi 的 python 包装器
– PyKaldi,PyKaldi2 享有 Kaldi 和 Py-Torch 的深度集成,因此它可以支持最常用的序列判别训练标准,如 MMI、sMBR 和 MPE。为了训练管道的简单性和灵活性以及模型的鲁棒性,PyKaldi2 具有动态晶格生成、对齐生成和数据模拟。从 Librispeech 的基准实验中,我们已经表明序列训练管道可以提供超过 CE 模型的预期收益。我们还通过对重放的 Librispeech 评估数据进行评估,证明了 PyKaldi2 中数据模拟模块的有效性。目前,PyKaldi2 针对基于格的序列训练进行了优化。未来的工作之一是改进无格技术的配方。
D.Povey、A. Ghoshal、G. Boulianne、L. Burget、O. Glembek、
N.Goel、M. Hannemann、P. Motlıcek、Y. Qian、P. Schwarz,
J.Silovsky´、G. Semmer 和K.Vesely´,“Kaldi 语音识别工具包”,Proc。 ASRU,2011 年。
R.Marxer,“稳健语音识别中环境、麦克风和数据模拟不匹配的分析”,Computer Speech & Language,vol. 46,第 535-557 页,2017 年。
E. Vincent、B. Raj 和 T. Virtanen,“Dcase 2017 挑战设置:任务、数据集和基线系统”,2017 年。
X. Na、Y. Wang 和 S. Khudanpur,“基于无格的 mmi 的纯序列训练的 asr 神经网络”,Proc。演讲间,2019。